영화 검색어를 입력하면 국가별 Top3 영화 목록 및 평점 평균 가져오기
1. 네이버 개발자센터 API이용신청
2. client_id, client_secret 확인
3. 예제 코드 실행 및 결과확인
4. 응용 : 영화 검색어의 영화 목록 및 평점 집계
1. 네이버 개발자센터 API이용신청
네이버 API를 이용하기 위해서는 가입 및 이용신청이 되어 있어야 합니다.
[네이버 개발자센터 API] API 이용신청 및 Application 등록방법
네이버 개발자센터에서 API 이용신청 및 Application을 등록하는 방법을 알아보겠습니다. 1. 사이트접속 2. 로그인 3. API 이용신청 및 Application 등록 4. 등록정보확인 1. 사이트 접속 아래의 네이버 개
yenpa.tistory.com
2. client_id, client_secret 확인
아래의 방법으로 확인이 가능하며 미리 알고 있다면 스킵하시면 됩니다.
[네이버 개발자센터 API] client_id, client_secret확인
네이버 개발자센터 사이트내에서 나의 client_id, client_secret을 확인해보겠습니다. 1. client_id, client_secret확인 사이트 내에서 Products > 검색을 클릭합니다. 하단의 오픈 API 이용 신청으로 이동합니다..
yenpa.tistory.com
3. 예제 코드 실행 및 결과확인
사이트 내에서 Products > 검색을 클릭합니다.
아래의 페이지에서 개발가이드를 클릭합니다.
좌측의 영화를 클릭합니다.
아래의 코드로 기본 뉴스의 데이터 수집이 가능합니다.
client_id, client_secret은 본인의 데이터 입력, query에는 검색할 단어를 입력하시면 됩니다.
import os
import sys
import urllib.request
client_id = "YOUR_CLIEND_ID"
client_secret = "YOUR_CLIENT_SECRET"
query='범죄'
encText = urllib.parse.quote(query)
url = "https://openapi.naver.com/v1/search/movie?query=" + encText # JSON 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
4. 응용 : 영화 검색어의 영화 목록 및 평점 집계
목표 : 검색하는 단어를 국가별로 영화 결과 100 씩을 수집하고,
국가별로 평점순 상위 3개의 영화를 집계.
국가별 영화 100개의 평점 평균을 집계.
필요한 라이브러리를 import합니다.
import os
import sys
import urllib.request
import json
import pandas as pd영화 API 결과를 수집하는 함수를 작성하겠습니다.
영화 결과중 response['item'] 의 결과만 DataFrame으로 변환하고
나중 국가별로 집계를 위해 국가코드 column을 추가합니다.
def getresult(client_id,client_secret,query,country,display=10,start=1,sort='sim'):
encText = urllib.parse.quote(query)
url = "https://openapi.naver.com/v1/search/movie?query=" + encText + \
"&display=" + str(display) + "&start=" + str(start) + "&sort=" + sort + "&country=" + country
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
response_json = json.loads(response_body)
else:
print("Error Code:" + rescode)
result=pd.DataFrame(response_json['items'])
result['country']=country #국가코드 column추가
return resultclient_id, client_secret은 본인의 데이터 입력이 필요합니다.
검색어는 '범죄'로 해보겠습니다.
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_SECRET"
query='범죄'
countries = ["FR","GB","HK","JP","KR","US","ETC"] #국가별 집계를 위해 리스트 생성
display=100
start=1
sort='sim'
result_all=pd.DataFrame()
# 국가별로 결과를 가져오기위한 코드
for country in countries:
result= getresult(client_id,client_secret,query,country,display,start,sort)
result_all=pd.concat([result_all,result])국가별로 평점이 높은 영화 중 3개만 별도의 dataframe에 저장합니다.
result_all.loc[result_all['country']==country,] : for문의 country와 일치하는 데이터만 집계합니다.
df.sort_values('userRating',ascending=False) : userRating이 높은 순으로 데이터를 정렬합니다.
df.iloc[:3,:] : 상위 3개만 집계합니다. 숫자를 5로 변경하면 상위 5개 집계가 됩니다.
result_all=result_all.astype({'userRating':float}) # 평점 타입을 object > float으로 변경
df_all=pd.DataFrame()
for country in countries:
df=result_all.loc[result_all['country']==country,] # country와 일치하는 데이터 집계
df=df.sort_values('userRating',ascending=False) # 평점이 높은순 정렬
df_top=df.iloc[:3,:] # 상위 3개만 집계
df_all=pd.concat([df_all,df_top])title,country,pubDate,userRating 4개의 column만 확인해봅니다.
df_all[['title','country','pubDate','userRating']]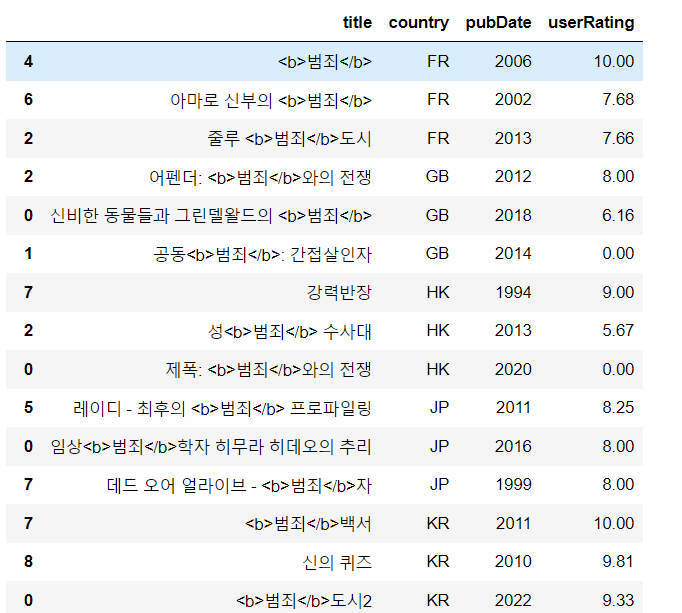
추가로 국가별 평점 평균과 영화 수를 확인합니다.
userRating과 country column으로 평점평균과 영화수를 집계합니다.
result_gr=result_all[['userRating','country']].groupby(['country']).mean() # 국가별 평점평균
result_gr['영화수']=result_all[['userRating','country']].groupby(['country']).count() #국가별 영화수 집계
result_gr
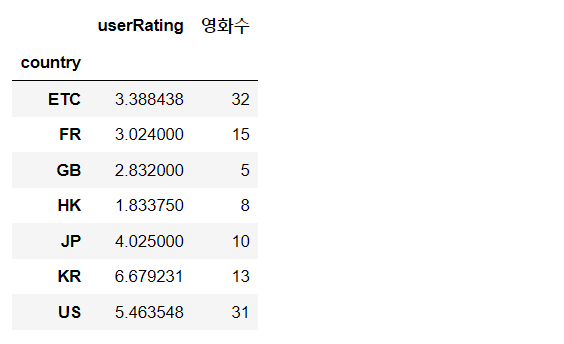
이상으로 영화 검색어에 대한 국가별 Top3 영화 목록 및 평점 평균 데이터를 확인해봤습니다.
'API' 카테고리의 다른 글
| [네이버 개발자센터 API] 통합 검색어 트렌드 데이터 가져오기(파이썬) (6) | 2022.10.07 |
|---|---|
| [네이버 개발자센터 API] 키워드로 블로그 순위에 들어갈 비율을 추정 (9) | 2022.10.06 |
| [네이버 개발자센터 API] 뉴스 검색어의 날짜별 건수 가져오기(파이썬) (4) | 2022.10.04 |
| [네이버 개발자센터 API] client_id, client_secret확인 (4) | 2022.10.04 |
| [네이버 개발자센터 API] 블로그 API를 이용해서 나의 포스팅 순위 검색(파이썬) (19) | 2022.10.03 |



