FinanceDataReader에서 주가를 가져와 한국거래소의 업종정보와 병합해서 업종별 수익률 및 MDD등의
데이터를 비교해보겠습니다.
FinanceDataReader의 설치 및 기본 사용법이 필요하신 분은 1번 참조 부탁드립니다.
1. FinanceDataReader 설치 및 주가정보 확인(Skip가능)
2. 한국거래소 업종분류 데이터 다운로드
3. 주가 수집 및 CAGR, MDD 계산
4. 업종별 결과확인
1. FinanceDataReader 설치(Skip가능)
[FinanceDataReader] 설치 및 주식 주가 정보 가져오기(코스피, 코스닥)
국내 주식 정보를 가져와 보겠습니다. FinanceDataReader의 수집데이터의 변경이 있었네요. 내용 수정했습니다(2022/11/09) 1. FinanceDataReader 설치 2. 종목 정보 가져오기 3. 주가 정보 가져오기 1. FinanceDataR
yenpa.tistory.com
2. 한국거래소 업종분류 데이터 다운로드
한국거래소 정보시스템(http://data.krx.co.kr/contents/MDC/MAIN/main/index.cmd) 접속 후
위쪽 메뉴의 통계 > 기본통계로 이동 후 좌측의 주식 > 세부안내 > 업종분류 현황을 클릭합니다.
아래의 정보를 선택 후 다운로드를 실시합니다.

아래 첨부파일을 다운받으셔도 됩니다.
임의의 폴더에 두시고 데이터를 불러옵니다.
dflist=pd.read_csv('e:/업종_20221117.csv')
dflist.head()
3. 주가 수집 및 CAGR, MDD 계산
전체 회사에 대해서 2017-01-01~오늘 날짜의 주가 정보를 수집합니다.
#전체 회사에 대해 기간별 주가정보 수집
price_all=pd.DataFrame()
for i, r in dflist.iterrows():
stock_code = r['종목코드']
#주가정보
code=stock_code
sdate='2017-01-01'
today=datetime.datetime.now().strftime('%Y%m%d')
price=fdr.DataReader(code,sdate,today)[['Close','Change']]
price['stock_code']=stock_code
price_all = pd.concat([price_all,price])
price_all회사별 종가(Close)와 일별 수익률(Change)이 잘 표시가 됩니다.
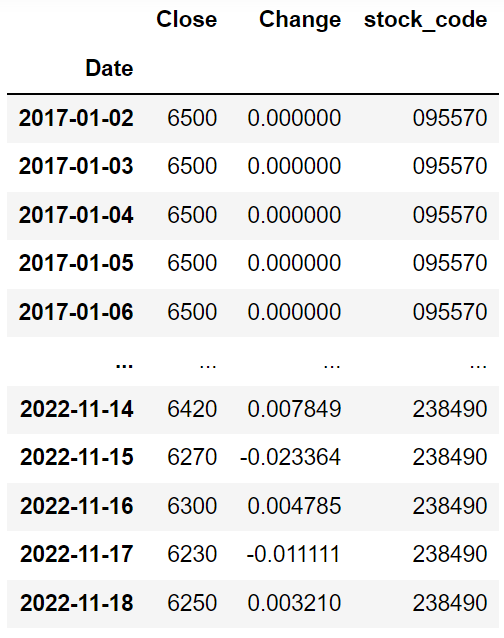
다음으로는 회사별 CAGR, MDD를 계산해 보겠습니다.
price_all이라는 DataFrame에 전체 회사의 정보가 들어가 있으니,
각각의 회사에 대해서 CAGR, MDD의 계산을 위해 for문을 실행합니다.
조건은 거래일 1년 이상인 회사만으로 했습니다.
(5년치 2000개 이상의 회사다보니 시간이 걸리네요)
#CAGR, MDD등의 정보수집 : 시간너무오래걸림(주의)
result_list=[]
for i, r in dflist.iterrows():
result={}
stock_code = r['종목코드']
price = price_all.loc[price_all['stock_code']==stock_code].copy()
print(str(i) + ',' + str(price.shape[0]))
if price.shape[0]<250:
print('continue')
continue
result['stock_code']=stock_code
#CAGR
cagr_result=((price['Change'] + 1).cumprod())
경과년도=(cagr_result.index[-1]-cagr_result.index[0]).days / 365
result['cagr'] = round((cagr_result.iloc[-1] ** (1/경과년도) -1)*100,1)
#MDD
price['max'] = 0
for j, r1 in price.iterrows():
maxval = price.loc[:j,'Close'].max()
price.loc[j,'max']=maxval
price['drawdown'] = (price['Close']/price['max']-1)*100
result['mdd'] = round(price['drawdown'].min(),1)
result_list.append(result)전체 회사의 계산 결과를 저장할 list입니다. 나중에 DataFrame으로 변환합니다.
result_list=[]회사별 stock_code, CAGR, MDD를 저장할 dictionary입니다.
result={}거래일이 1년 정도안된 회사는 건너뜁니다.
if price.shape[0]<250:
continueCAGR, MDD를 계산 후 result_list에 추가했습니다.
#CAGR
cagr_result=((price['Change'] + 1).cumprod())
경과년도=(cagr_result.index[-1]-cagr_result.index[0]).days / 365
result['cagr'] = round((cagr_result.iloc[-1] ** (1/경과년도) -1)*100,1)
#MDD
price['max'] = 0
for j, r1 in price.iterrows():
maxval = price.loc[:j,'Close'].max()
price.loc[j,'max']=maxval
price['drawdown'] = (price['Close']/price['max']-1)*100
result['mdd'] = round(price['drawdown'].min(),1)
result_list.append(result)
4. 업종별 결과확인
우선 3번에서 만든 result_list를 DataFrame으로 변환합니다.
그리고 2번에서 만든 업종 정보에 병합합니다.
dfprice=pd.DataFrame(result_list)
df=pd.merge(left=dflist,right=dfprice,how='left',
left_on='종목코드',right_on='stock_code')
df우측에 cagr, mdd가 추가된 것을 알 수 있습니다.
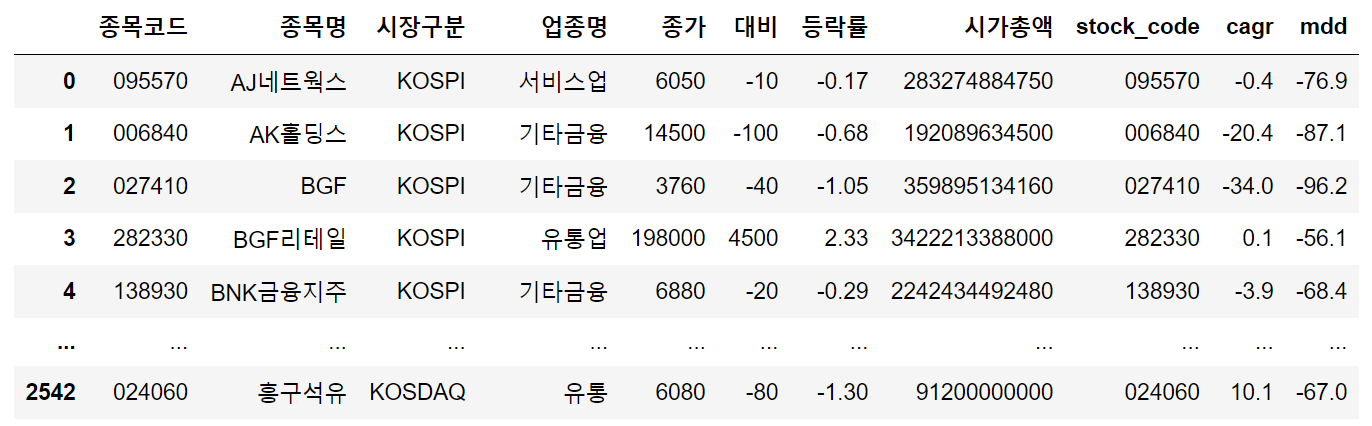
총 54개의 업종명이 검색이 됩니다.
len(df['업종명'].unique())
업종별 cagr 평균순으로 그래프를확인하겠습니다.
mean_df=df.groupby('업종명').mean().sort_values('cagr',ascending=True)[['cagr','mdd']]
fig=px.bar(data_frame=mean_df,y=mean_df.index,x='cagr',color='mdd')
fig.show()기타제조가 가장 높았고, 전기전자, 운송순으로 높았습니다.
은행의 cagr이 가장 낮았네요
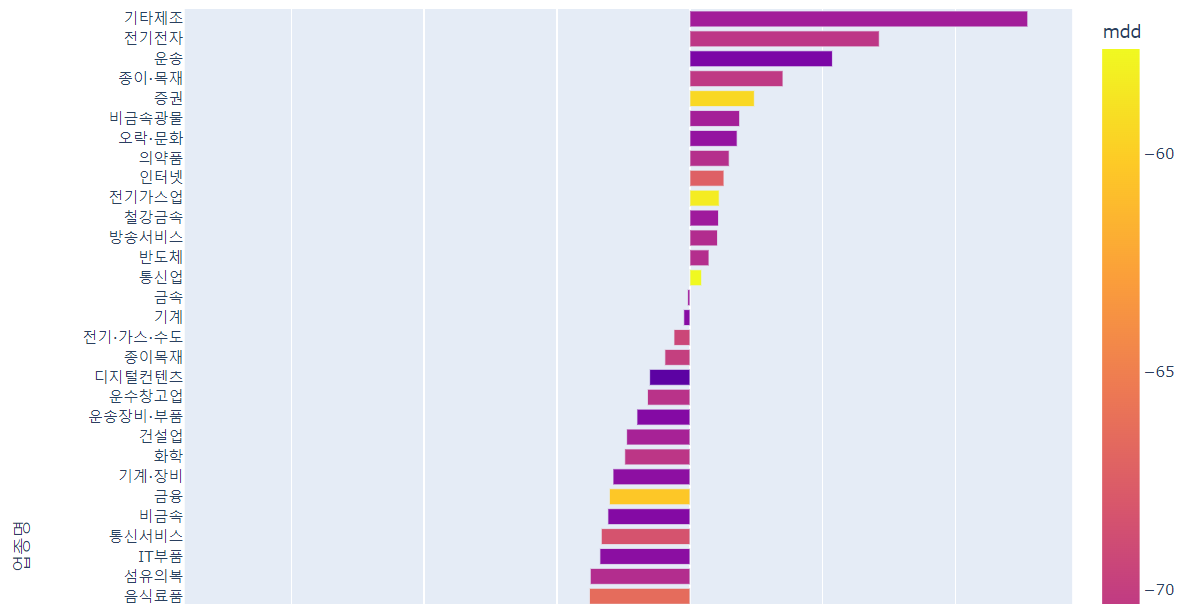
은행 및 의료정밀, 소프트웨어의 평균이 낮았습니다.
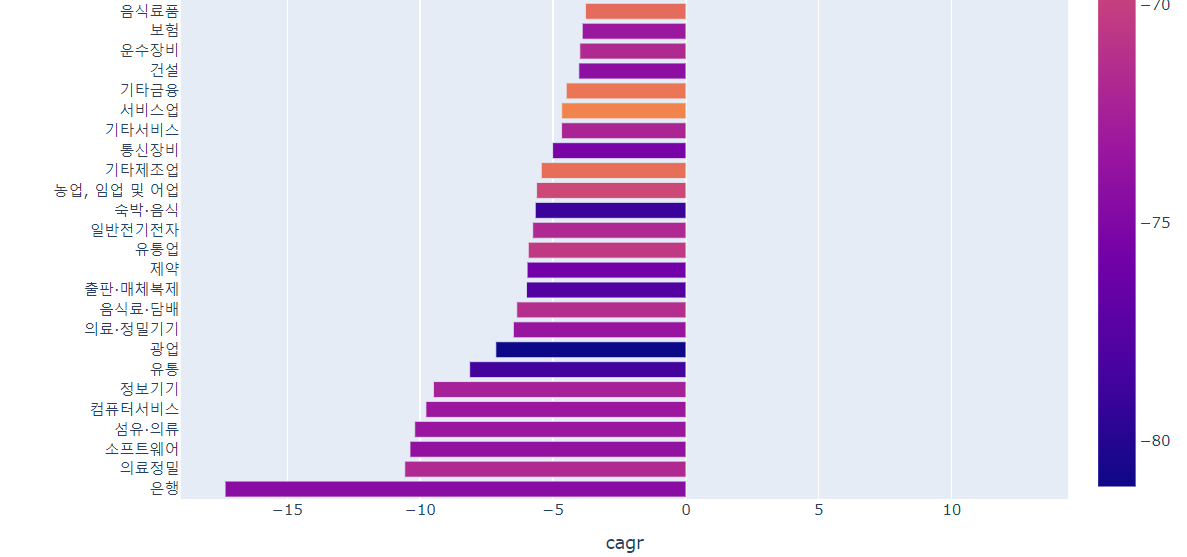
업종별 MDD평균을 구해볼까요
mean_df=df.groupby('업종명').mean().sort_values('mdd',ascending=True)[['cagr','mdd']]
fig=px.bar(data_frame=mean_df,y=mean_df.index,x='mdd',color='cagr',height=1000)
fig.show()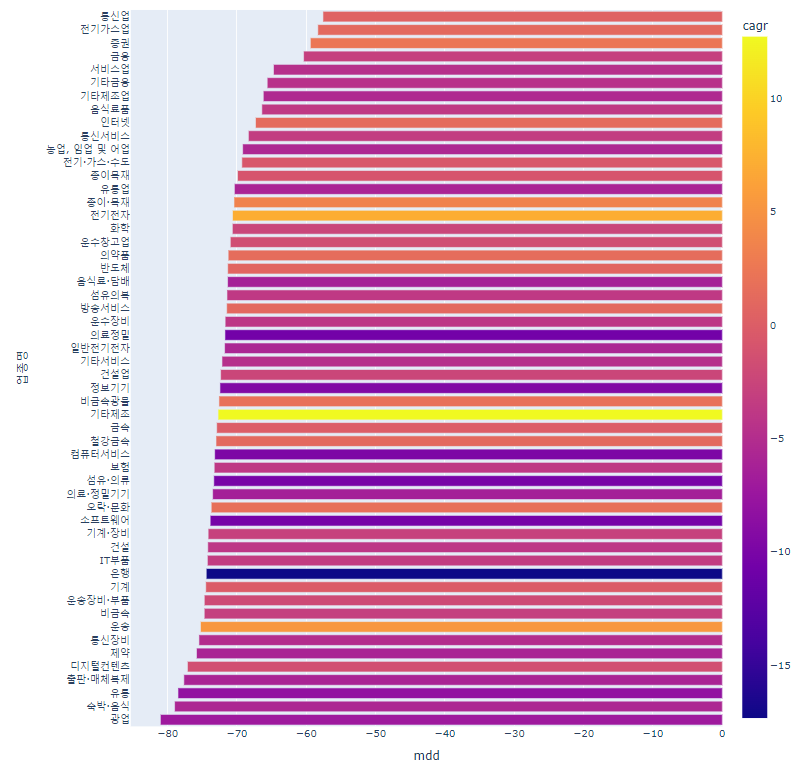
업종별 cagr top3를 구해 cagr이 높은순으로 정렬했습니다.
top3=df.sort_values('cagr',ascending=False).groupby('업종명').head(3).sort_values('cagr',ascending=True)
fig=px.bar(data_frame=top3,y='종목명',x='cagr',color='mdd',height=1000)
fig.show()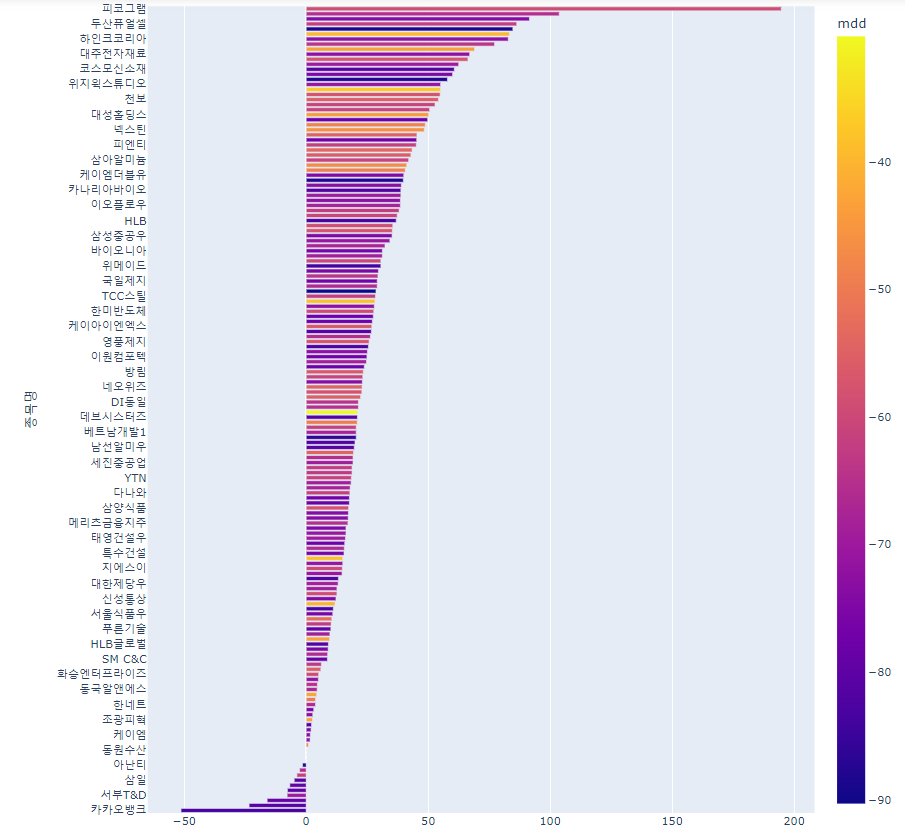
반대로 cagr이 낮은순으로 top를 그려봤습니다.
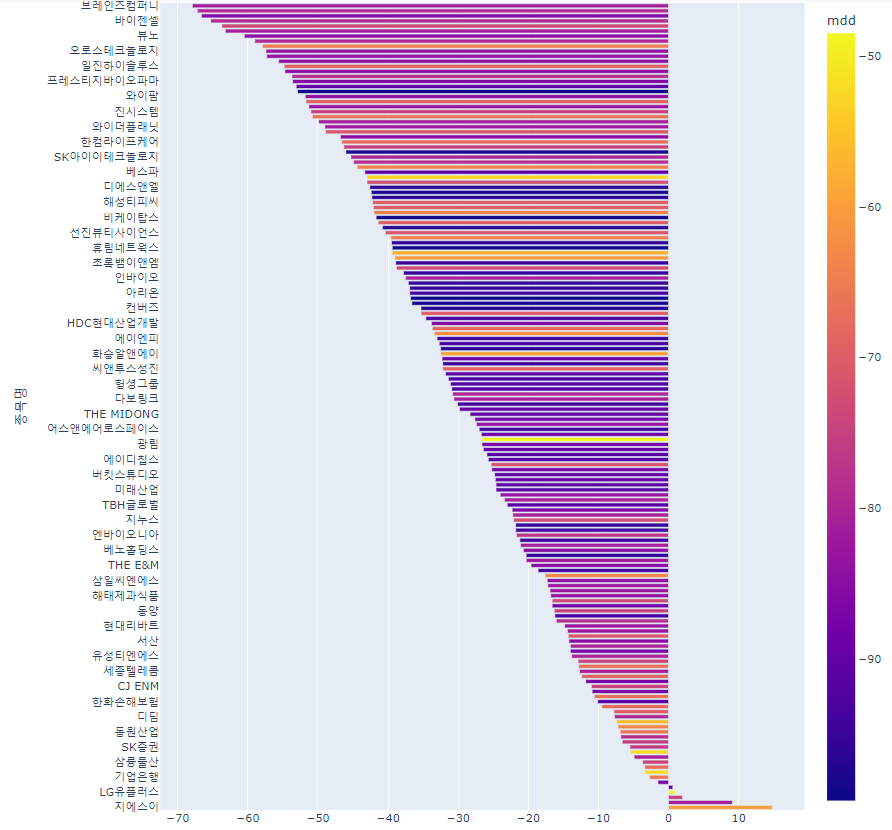
색깔을 MDD로 구분했는데 밝은 색일수록 MDD가 낮은 수치입니다.
cagr이 높고 MDD가 낮은 것을 찾으면 좋겠죠.
plotly로 그래프를 그려서 마우스를 올리면 cagr, MDD, 회사명이 확인도 할수 있습니다.
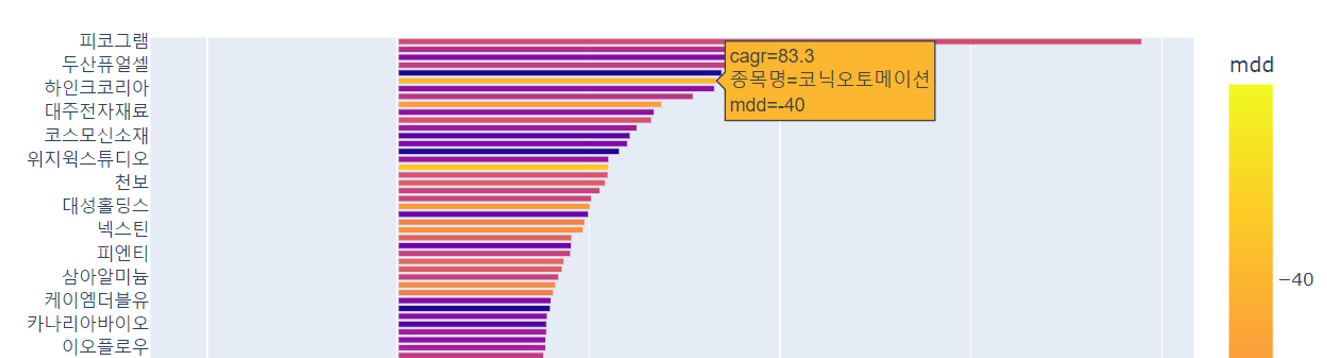
마직막으로 MDD -50% 이상의 회사 중 cagr이 높은 순으로 그래프를 그려보겠습니다.
top3=df.loc[df['mdd']>-50].sort_values('cagr',ascending=False). \
sort_values('cagr',ascending=True)
fig=px.bar(data_frame=top3,y='종목명',x='cagr',color='mdd',height=1000)
fig.show()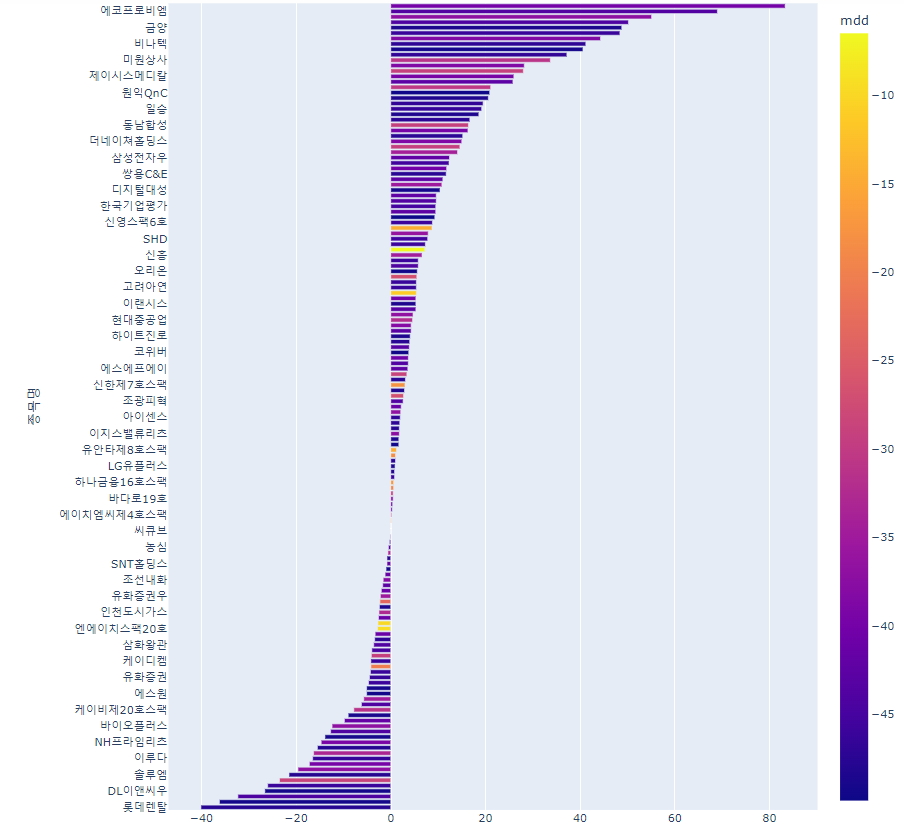
이상으로 FinanceDataReader에서 주가를 가져와 한국거래소의 업종정보와 병합해서 cagr및 MDD를 확인해봤습니다.
'API' 카테고리의 다른 글
| [Fred API] 가입 후 API KEY 신청 및 확인하기 (4) | 2022.11.23 |
|---|---|
| [네이버 개발자센터 API] 지역 인기 핫 플레이스 정보 가져오기 (6) | 2022.11.21 |
| [FinanceDataReader] 주가 및 MDD(Maximum DrawDown) 확인 (6) | 2022.11.18 |
| [전자공시 Dart API] PER 계산 및 PER 낮은 회사 순으로 정렬하기 (4) | 2022.11.16 |
| [전자공시 Dart API] PBR 계산 및 낮은 회사 리스트 수집 (6) | 2022.11.14 |



