전자공시 Dart API를 이용해서 유통주식 비율이 낮은(자기주식 비율이 높은) 회사 리스트를 가져와보겠습니다.
가입이 되어 있으신분은 2번부터 진행하시면 됩니다.
1. 가입 및 인증키 확인(Skip 가능)
2. 전체 회사리스트 수집
3. 발행주식수 및 유통주식수, 자기주식수 정보 수집
4. 유통주식수 비율이 낮은 회사 확인
1. 가입 및 인증키 확인(Skip 가능)
[전자공시 Dart API] 가입 및 인증키(API Key) 확인하기
1. 사이트 가입 2. 인증키(API Key) 확인하기 1. 사이트 가입 사이트에 접속합니다. https://opendart.fss.or.kr/ 전자공시 OPENDART 시스템 --> 시스템 점검으로 모든 서비스 이용이 일시적으로 중단되어니 양
yenpa.tistory.com
2. 전체 회사리스트 수집
전자공시 API의 공시정보 > 고유번호를 이용해서 전체 회사리스트를 다운받아
압축을 해제하고 결과를 DataFrame에 저장하는 코드입니다.
path는 본인의 PC에 저장하고 싶은 Directory를 지정합니다.
저의 경우는 임의로 path='E:/' 로 지정했습니다.
crtfc_key는 본인의 데이터 입력이 필요합니다.
import io
import zipfile
import requests
from xml.etree.ElementTree import parse
import pandas as pd
import time
import datetime
crtfc_key='YOUR_APIKEY'
#회사정보 가져오기
#임의로 'E:/' 로 설정 및 다운로드 파일 corpcode.zip으로 설정
path='E:/'
filename='corpcode.zip'
url = 'https://opendart.fss.or.kr/api/corpCode.xml'
params = {
'crtfc_key': crtfc_key,
}
results=requests.get(url, params=params)
file = open(path+filename, 'wb')
file.write(results.content)
file.close()
zipfile.ZipFile(path+filename).extractall(path)
tree = parse(path + 'CORPCODE.xml')
root = tree.getroot()
li=root.findall('list')
corp_code,corp_name,stock_code,modify_date=[],[],[],[]
for d in li:
corp_code.append(d.find('corp_code').text)
corp_name.append(d.find('corp_name').text)
stock_code.append(d.find('stock_code').text)
modify_date.append(d.find('modify_date').text)
corps_df = pd.DataFrame({'corp_code':corp_code,'corp_name':corp_name,
'stock_code':stock_code,'modify_date':modify_date})
corps_df = corps_df.loc[corps_df['stock_code']!=' ',:].reset_index(drop=True)전체 회사리스트를 e:/corpcode.zip 이라는 경로의 파일명으로 저장합니다.
path='E:/'
filename='corpcode.zip'
url = 'https://opendart.fss.or.kr/api/corpCode.xml'
params = {
'crtfc_key': crtfc_key,
}
results=requests.get(url, params=params)
file = open(path+filename, 'wb')
file.write(results.content)
file.close()다운로드 받은 zip file을 압축 해제합니다.
zipfile.ZipFile(path+filename).extractall(path)압축 해제한 xml파일의 내용에서 회사 정보들을 가져와서 corps_df라는 DataFrame에 저장합니다.
corps_df 내용중 회사의 stock_code(주식코드)가 있는 회사만 다시 저장합니다.
tree = parse(path + 'CORPCODE.xml')
root = tree.getroot()
li=root.findall('list')
corp_code,corp_name,stock_code,modify_date=[],[],[],[]
for d in li:
corp_code.append(d.find('corp_code').text)
corp_name.append(d.find('corp_name').text)
stock_code.append(d.find('stock_code').text)
modify_date.append(d.find('modify_date').text)
corps_df = pd.DataFrame({'corp_code':corp_code,'corp_name':corp_name,
'stock_code':stock_code,'modify_date':modify_date})
corps_df = corps_df.loc[corps_df['stock_code']!=' ',:].reset_index(drop=True)
3. 발행주식수 및 유통주식수, 자기주식수 정보 수집
2번에서 구한 회사별로 사업보고서 주요정보 > 주식의 총수의 정보를 가져와서
그 중 필요한 정보인 발행주식의 총수, 유통주식수, 자기주식수만을 따로 저장합니다.
#전체 결과 저장
result_all=[]
print('총 회사수는 : ' + str(corps_df.shape[0]))
# 수집한 회사에 대해서 for문.
for i, r in corps_df.iterrows():
#if i == 1:
# break
#없으면 어느 시점에서 에러발생
time.sleep(0.03)
print('i = ' + str(i))
corp_code=str(r['corp_code'])
corp_name=r['corp_name']
stock_code=str(r['stock_code'])
bsns_year=2021
reprt_code='11011'
#1분기보고서 : 11013, 반기보고서 : 11012, 3분기보고서 : 11014, 사업보고서 : 11011
url = 'https://opendart.fss.or.kr/api/stockTotqySttus.json'
params = {
'crtfc_key': crtfc_key,
'corp_code' : corp_code,
'bsns_year' : str(bsns_year),
'reprt_code' : reprt_code,
}
results = requests.get(url, params=params).json()
# 응답이 정상 '000' 일 경우에만 데이터 수집
if results['status'] == '000':
for result in results['list']:
if result['se'] in ['보통주','우선주','합계']:
result_dic={}
result_dic['se']=result['se']
result_dic['istc_totqy']=result['istc_totqy']
result_dic['tesstk_co']=result['tesstk_co']
result_dic['distb_stock_co']=result['distb_stock_co']
result_dic['corp_code']=corp_code
result_dic['corp_name']=corp_name
result_dic['stock_code']=stock_code
result_all.append(result_dic)
stocks=pd.DataFrame(result_all)
stocks.columns=['구분','발행주식의총수','자기주식수','유통주식수','회사코드','회사명','주식코드']
stocks전체 결과를 저장할 list입니다. 나중에 DataFrame으로 변환이 됩니다.
#전체결과저장
result_all=[]회사 별로 정보를 확인하기 위해 for문을 작성했고, time.sleep(0.3)은 for문 별로 잠시 delay를 주기 위해 넣었습니다.
이 부분이 없으면 에러가 나는 경우가 있습니다. 0.3으로 해도 에러가 나기도 합니다.
# 수집한 회사에 대해서 for문.
for i, r in corps_df.iterrows():
#if i == 1:
# break
#없으면 어느 시점에서 에러발생
time.sleep(0.03)필요한 회사 정보를 저장하고, corp_code를 이용해서 주식의 총수 API로 데이터를 가져옵니다.
2021년의 사업보고서 기준으로 주식수를 가져오겠습니다.
print('i = ' + str(i))
corp_code=str(r['corp_code'])
corp_name=r['corp_name']
stock_code=str(r['stock_code'])
bsns_year=2021
reprt_code='11011'
#1분기보고서 : 11013, 반기보고서 : 11012, 3분기보고서 : 11014, 사업보고서 : 11011
url = 'https://opendart.fss.or.kr/api/stockTotqySttus.json'
params = {
'crtfc_key': crtfc_key,
'corp_code' : corp_code,
'bsns_year' : str(bsns_year),
'reprt_code' : reprt_code,
}
results = requests.get(url, params=params).json()정상응답 '000'인 회사의 경우만 사용합니다.
각 회사별로 보통주, 우선주, 합계의 정보를 각 각 result_dic이라는 dictionary 로 만든후에
result_all의 list에 추가 합니다.
if results['status'] == '000':
for result in results['list']:
if result['se'] in ['보통주','우선주','합계']:
result_dic={}
result_dic['se']=result['se']
result_dic['istc_totqy']=result['istc_totqy']
result_dic['tesstk_co']=result['tesstk_co']
result_dic['distb_stock_co']=result['distb_stock_co']
result_dic['corp_code']=corp_code
result_dic['corp_name']=corp_name
result_dic['stock_code']=stock_code
result_all.append(result_dic)result_all을 stocks라는 DataFrame으로 변환 후에 colum명을 알기 쉬운 이름으로 변경합니다.
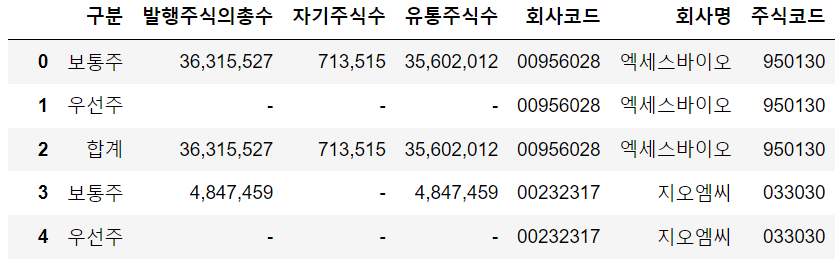
stocks의 내용을 볼까요
stocks=pd.DataFrame(result_all)
stocks.columns=['구분','발행주식의총수','자기주식수','유통주식수','회사코드','회사명','주식코드']
stocks정보를 잘 가져오는 것을 알수 있습니다. 엑세스바이오의 경우는 우선주가 없는 회사이므로 -로 되어 있는데,
우선주가 있는 회사는 우선주 데이터가 정상적으로 표시됩니다.
4. 유통주식수 비율이 낮은 회사 확인
그럼 이제 오늘의 목표인 유통주식수 비율이 낮은 회사 리스트를 확인해보겠습니다.
우선 숫자 데이터의 사이에 ','가 들어가 있어 이것을 제거하고, 주식수가 없는 데이터는 0으로 치환합니다.

import matplotlib.pyplot as plt
import seaborn as sns
import seaborn as sns
sns.set_theme(style="whitegrid")
plt.rc('font', family='NanumGothic')
# int로 변환하기 위해 숫자사이의 ',' 정보를 삭제
stocks['발행주식의총수']=stocks['발행주식의총수'].str.replace(',','')
stocks['자기주식수']=stocks['자기주식수'].str.replace(',','')
stocks['유통주식수']=stocks['유통주식수'].str.replace(',','')
# 주식수가 '-'로 표시되는 데이터는 0으로 변환
stocks.loc[stocks['발행주식의총수']=='-','발행주식의총수']=0
stocks.loc[stocks['자기주식수']=='-','자기주식수']=0
stocks.loc[stocks['유통주식수']=='-','유통주식수']=0
stocks
비율을 계산하기 위해 발행주식의총수, 자기주식수, 유통주식수의 column type을 int64로 변경합니다.
# column type변경
stocks[['발행주식의총수','자기주식수','유통주식수']]= \
stocks[['발행주식의총수','자기주식수','유통주식수']].astype('int64')
stocks.dtypes
유통주식비율 및 자기주식비율을 계산합니다.
총주식비율=유통주식수+자기주식수 이므로 유통주식비율=100%-자기주식비율이 됩니다.
stocks['유통주식비율']=stocks['유통주식수']/stocks['발행주식의총수']*100
stocks['자기주식비율']=stocks['자기주식수']/stocks['발행주식의총수']*100
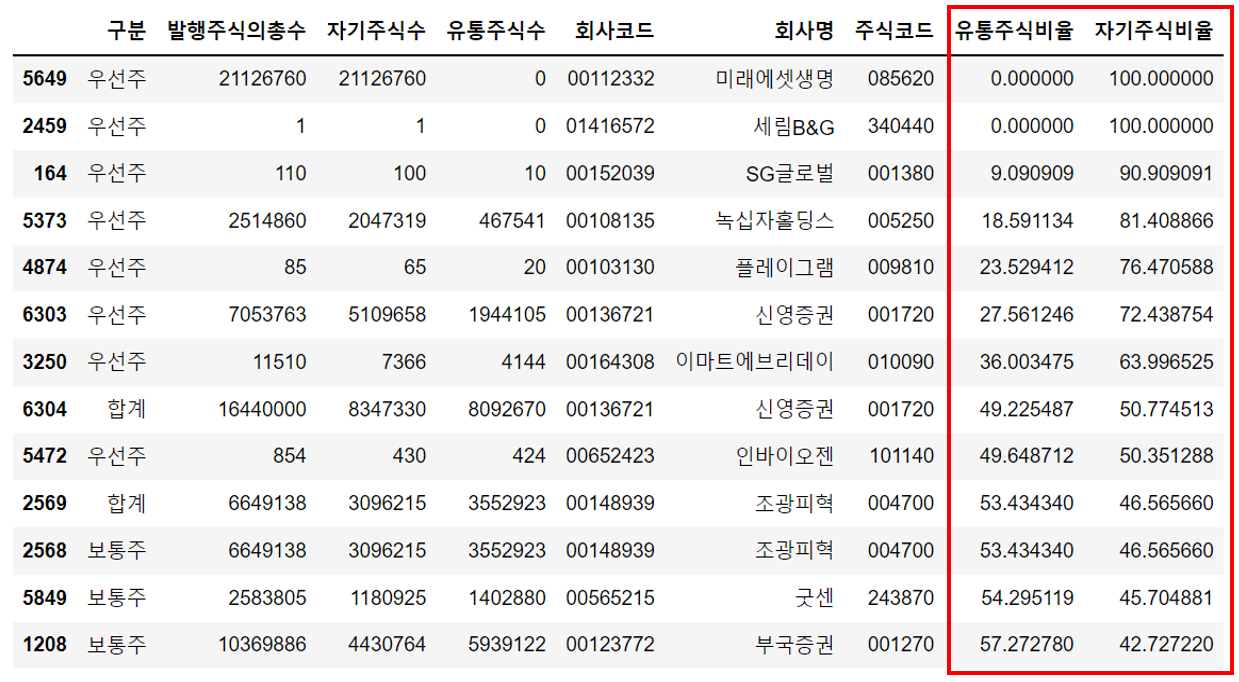
유통주식비율 하위 20개만 확인해볼까요
stocks20=stocks.sort_values('유통주식비율',ascending=True).iloc[:20]
stocks20아래와 같은 결과를 확인할 수 있습니다.
그래프로도 한번 보겠습니다.
sns.barplot(data=stocks20,x='유통주식비율',y=(stocks20['회사명'] + '_' + stocks20['구분']))
plt.title('유통주식비율')
plt.show()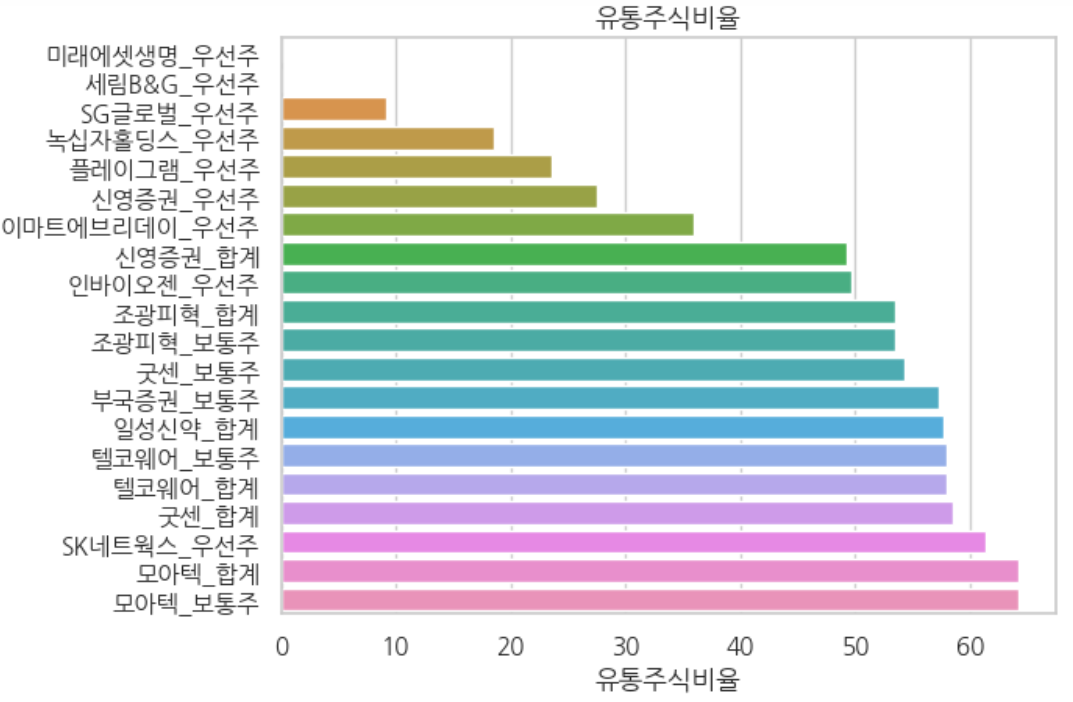
이상으로 유통주식 비율이 낮은(자기주식 비율이 높은) 회사 리스트를 확인해봤습니다.
'API' 카테고리의 다른 글
| [전자공시 Dart API] 전체 상장 회사의 재무제표(단일회사 전체 재무제표) 수집 (4) | 2022.11.07 |
|---|---|
| [전자공시 Dart API] 전체 상장 회사의 상세정보(기업개황) 수집 및 저장 (19) | 2022.11.07 |
| [네이버 API] 블로그 나만의 키워드 마스터 만들기 두번째(파이썬) (5) | 2022.11.04 |
| [아파트 실거래가 API] 월간 가격상승 Top 및 거래량 Top확인하기 (4) | 2022.11.03 |
| [전자공시 Dart API] 회사분할결정 공시후 주가 확인 (4) | 2022.11.02 |


