한국은행 API를 이용해서 우리나라 기준 금리데이터와 국채 수익률(3년, 10년) 데이터를 수집하고
각 스프레드 데이터를 계산 후 그래프로 확인해 보겠습니다.
확인을 위해서는 한국은행 API에 가입이 되어 있어야 합니다.
1. 한국은행 API 가입
2. 기준금리
3. 국채 수익률(3년, 10년)
4. 기준금리-국채수익률 스프레드
5. 스프레드와 코스피
1. 한국은행 API 가입
[한국은행 API] 인증키 신청 및 100대 통계 지표 수집
한국은행 API에 가입하고 서비스 항목 중 100대 통계지표에 대해 데이터 수집하고 그래프로 확인해보겠습니다. 1. 인증키 신청 2. 인증키 확인 3. 100대 통계 지표 수집 1. 인증키 신청 사이트 접속
yenpa.tistory.com
2. 기준금리
한국은행 API의 통계조회 조건 설정의 서비스에서 통계항목코드 1을 '722Y001'로
지정하면 한국은행 기준 금리 및 여수신 금리에 대한 정보를 불러올 수 있습니다.
아래는 금리에 대한 정보(722Y001)를 20221201~20221217 기간에서 일별로 조회한 코드입니다.
수집가능한 데이터 항목을 확인하기 위해 단기로 우선 수집했고, 나중에 한국은행 기준금리만 장기로 수집하겠습니다.
import requests
url = 'https://ecos.bok.or.kr/api/StatisticSearch/' + apikey \
+ '/json/kr/1/100/722Y001/D/20221201/20221217'
response = requests.get(url)
result = response.json()
list_total_count=(int)(result['StatisticSearch']['list_total_count'])
list_count=(int)(list_total_count/100) + 1
rows=[]
for i in range(0,list_count):
start = str(i * 100 + 1)
end = str((i + 1) * 100)
url = 'https://ecos.bok.or.kr/api/StatisticSearch/' + apikey + '/json/kr/' \
+ start + '/' + end + '/722Y001/D/20221201/20221217'
response = requests.get(url)
result = response.json()
rows = rows + result['StatisticSearch']['row']
df=pd.DataFrame(rows)
df
수집된 데이터의 ITEM_NAME1에서 항목을 확인할 수 있는데 한국은행 기준금리 외에도 여러 가지 데이터가 수집이 가능합니다.
df['ITEM_NAME1'].unique()
한국은행 기준금리의 ITEM_CODE1이 0101000인데 이 코드로 장기데이터(20060101~20230315)를 수집하겠습니다.
#장기데이터수집
url = 'https://ecos.bok.or.kr/api/StatisticSearch/' + apikey \
+ '/json/kr/1/100/722Y001/D/20060101/20230315/0101000'
response = requests.get(url)
result = response.json()
list_total_count=(int)(result['StatisticSearch']['list_total_count'])
list_count=(int)(list_total_count/100) + 1
rows=[]
for i in range(0,list_count):
start = str(i * 100 + 1)
end = str((i + 1) * 100)
url = 'https://ecos.bok.or.kr/api/StatisticSearch/' + apikey + '/json/kr/' \
+ start + '/' + end + '/722Y001/D/20060101/20230315/0101000'
response = requests.get(url)
result = response.json()
rows = rows + result['StatisticSearch']['row']
df=pd.DataFrame(rows)
dfTIME Column이 YYYYMMDD의 object형식인데 Datetime Column으로 만들고,
Data_value는 float으로 변경 후 필요한 Column만 따로 저장했습니다.
df1=df[['ITEM_NAME1','TIME','DATA_VALUE']]
df1['date']=pd.to_datetime((df1['TIME'].str[:4] + '-' + df1['TIME'].str[4:6] + '-' + df1['TIME'].str[6:8]))
df1=df1.astype({'DATA_VALUE':'float'})
df1=df1.drop_duplicates()
df1
그래프로 확인하겠습니다.

3. 국채 수익률(3년, 10년)
국채 3년과 10년에 대한 수익률을 수집하겠습니다.
3년은 통계항목코드 1을 '722Y001'와 ITEM_CODE1 '010200000'이고,
10년은 ITEM_CODE1 '010200000'로 수집이 가능합니다.
국채 3년 데이터를 수집하고 기준 금리와 동일하게 DataFrame을 수정하겠습니다.
url = 'https://ecos.bok.or.kr/api/StatisticSearch/' + apikey \
+ '/json/kr/1/100/817Y002/D/20060101/20230315/010200000'
response = requests.get(url)
result = response.json()
list_total_count=(int)(result['StatisticSearch']['list_total_count'])
list_count=(int)(list_total_count/100) + 1
rows=[]
for i in range(0,list_count):
start = str(i * 100 + 1)
end = str((i + 1) * 100)
url = 'https://ecos.bok.or.kr/api/StatisticSearch/' + apikey + '/json/kr/' \
+ start + '/' + end + '/817Y002/D/20060101/20230315/010200000'
response = requests.get(url)
result = response.json()
rows = rows + result['StatisticSearch']['row']
df3y=pd.DataFrame(rows)
df3y=df3y[['ITEM_NAME1','TIME','DATA_VALUE']]
df3y['date']=pd.to_datetime((df3y['TIME'].str[:4] + '-' + df3y['TIME'].str[4:6] + '-'+ df3y['TIME'].str[6:8]))
df3y=df3y.astype({'DATA_VALUE':'float'})
df3y=df3y.drop_duplicates()
df3y
10년도 동일하게 수집 후 처리하겠습니다.
url = 'https://ecos.bok.or.kr/api/StatisticSearch/' + apikey \
+ '/json/kr/1/100/817Y002/D/20060101/20230315/010210000'
response = requests.get(url)
result = response.json()
list_total_count=(int)(result['StatisticSearch']['list_total_count'])
list_count=(int)(list_total_count/100) + 1
rows=[]
for i in range(0,list_count):
start = str(i * 100 + 1)
end = str((i + 1) * 100)
url = 'https://ecos.bok.or.kr/api/StatisticSearch/' + apikey + '/json/kr/' \
+ start + '/' + end + '/817Y002/D/20060101/20230315/010210000'
response = requests.get(url)
result = response.json()
rows = rows + result['StatisticSearch']['row']
df10y=pd.DataFrame(rows)
df10y=df10y[['ITEM_NAME1','TIME','DATA_VALUE']]
df10y['date']=pd.to_datetime((df10y['TIME'].str[:4] + '-' + df10y['TIME'].str[4:6] + '-' + df10y['TIME'].str[6:8]))
df10y=df10y.astype({'DATA_VALUE':'float'})
df10y=df10y.drop_duplicates()
df10y
그래프로 보겠습니다.
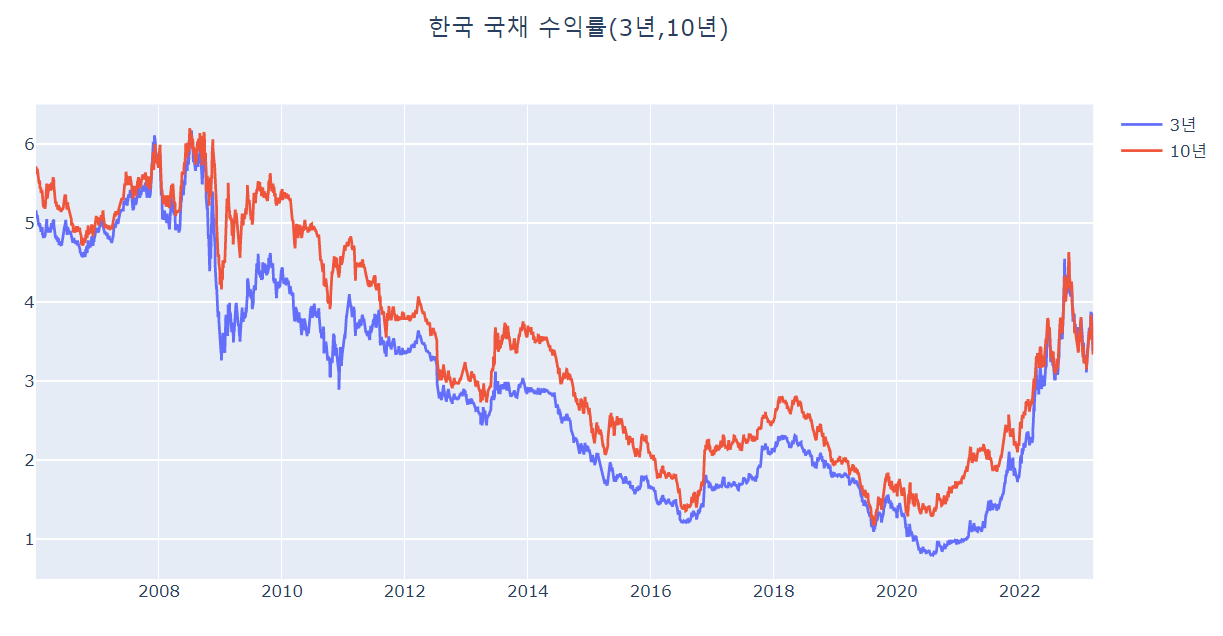
4. 기준금리-국채수익률 스프레드
기준금리와 국채 수익률의 스프레드를 계산하겠습니다.
우선 국채 3년과 10년를 병합하고, 기준금리 데이터와 inner방식으로 병합했습니다.
그리고 각각 3년-기준금리, 10년-기준금리의 column을 계산했습니다.
dfbond=pd.concat([df3y.set_index('date')[['DATA_VALUE']],df10y.set_index('date')[['DATA_VALUE']]], axis=1)
dfbond.columns=['국채3년','국채10년']
dfall=pd.merge(left=dfbond,right=df1.set_index('date')[['DATA_VALUE']],how='inner',left_index=True, right_index=True)
dfall=dfall.rename(columns={'DATA_VALUE':'기준금리'})
dfall['3년-기준금리']=dfall['국채3년']- dfall['기준금리']
dfall['10년-기준금리']=dfall['국채10년']- dfall['기준금리']
dfall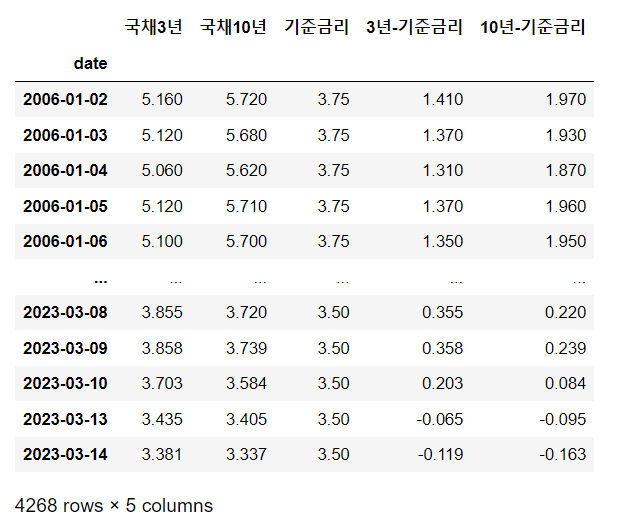
그래프로 보겠습니다.
fig = go.Figure()
fig.add_trace(
go.Scatter(x=dfall.index, y=dfall['3년-기준금리'], name="3년-기준금리"),
)
fig.add_trace(
go.Scatter(x=dfall.index, y=dfall['10년-기준금리'], name="10년-기준금리"),
)
fig.update_layout(title_text='국채수익률과 기준금리 스프레드', title_x=0.5)
fig.show()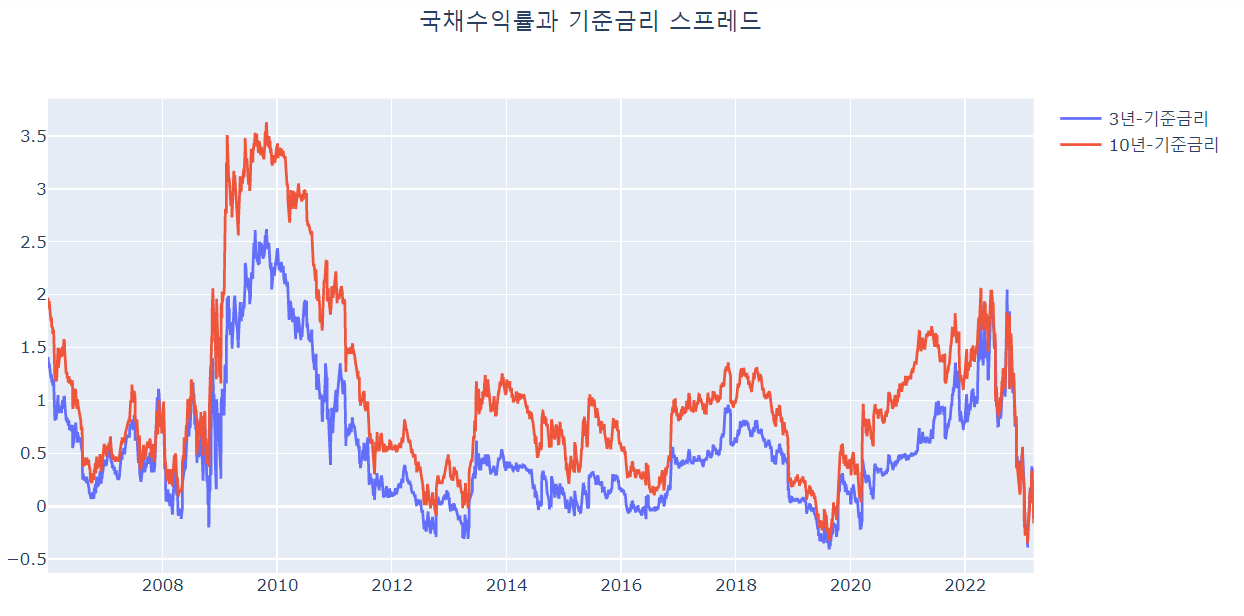
5. 스프레드와 코스피
yahoo finance를 이용해서 코스피 데이터를 수집하겠습니다.
기간은 금리데이터와 동일하게 설정했습니다.
import yfinance as yf
from datetime import datetime
enddate=datetime.now().strftime('%Y-%m-%d')
kospi=yf.download('^KS11', '2006-01-01', '2023-03-16', auto_adjust=True)
kospi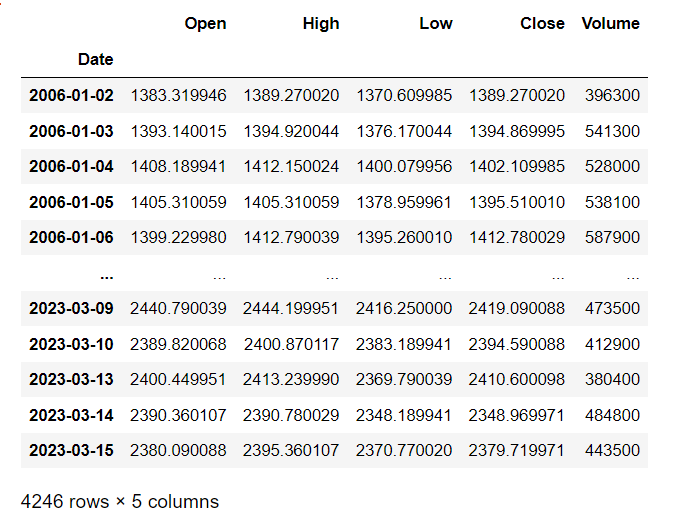
그래프로 확인하겠습니다.
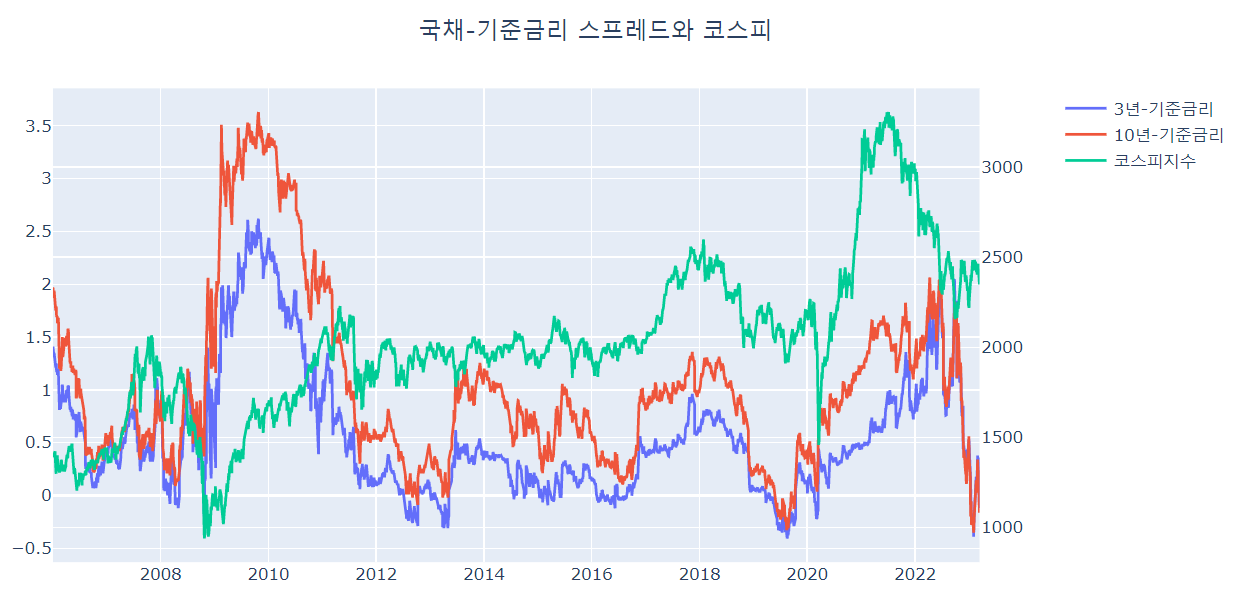
이상으로 기준 금리데이터와 국채 수익률(3년, 10년) 데이터를 수집하고 그래프로 확인하고,
코스피 데이터와 비교해 봤습니다.
'API' 카테고리의 다른 글
| [한국은행 API] 예금 대출 금리 스프레드 및 가계-기업대출 스프레드와 국채 수익률 (4) | 2023.03.27 |
|---|---|
| [Fred API] 미국 기준금리와 국채 수익률 스프레드 (8) | 2023.03.19 |
| [통계청 API] 해외 입국자의 국적,연령대,입국 목적별 정보수집(2022년) (4) | 2023.03.06 |
| [yahoo finance API] 금 은 구리 스프레드와 주가(S&P500) 비교 (4) | 2023.03.02 |
| [통계청 API] 서울 각 구별 초중고 학생 순 이동자수(2006년~2022년) (4) | 2023.02.28 |



