네이버 뷰를 크롤링해서 검색어에 대한 링크정보를 확인해 보겠습니다.
필요한 라이브러리를 import 합니다.
from bs4 import BeautifulSoup
from urllib.parse import quote
import requests
import datetime
import pandas as pd
경포대 맛집에 대한 네이버 뷰의 결과를 BeatifulSoup을 이용해서 가져옵니다.
keyword='경포대 맛집'
query = keyword.replace(' ', '+')
url = "https://search.naver.com/search.naver?where=view&sm=tab_viw.blog&query=" + query + '&nso='
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, "lxml")
review=soup.find('div', class_='review_loading _trigger_base')
posts = soup.find_all("li", attrs={"class": "bx _svp_item"})keyword는 검색어를 저장하는 변수입니다.
keyword='경포대 맛집'
query = keyword.replace(' ', '+')네이버 뷰의 url에 검색어를 추가해서 BeautifulSoup을 이용해서 결과를 저장합니다.
url = "https://search.naver.com/search.naver?where=view&sm=tab_viw.blog&query=" + query + '&nso='
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, "lxml")각 포스팅은 li (class "bx _svp_item")로 선택이 가능합니다.
한 페이지에 30개가 default로 표시되는데, posts도 30개가 저장이 됩니다.
posts = soup.find_all("li", attrs={"class": "bx _svp_item"})
한 개의 포스팅에 어떤 데이터가 있는지 보겠습니다.
posts[0]

그중에서 제목과 링크 정보만 따로 확인해 보겠습니다.
#제목
print(post.find("a", attrs={"class": "api_txt_lines"}).get_text())
#링크
print(post.find("a", attrs={"class": "sub_txt sub_name"}).attrs['href'])제목과 링크 정보가 정상적으로 수집된 것을 알 수 있습니다.
23-02-15일 결과인데, 날짜에 따라 다른 결과가 보일 수 있습니다.

그럼 30개 데이터에 대한 제목과 링크정보를 보겠습니다.
for i, post in enumerate(posts):
author = post.find("a", attrs={"class": "sub_txt sub_name"}).get_text()
title = post.find("a", attrs={"class": "api_txt_lines"}).get_text()
href=post.find("a", attrs={"class": "sub_txt sub_name"}).attrs['href']
print(title)
print(href)
링크에 대한 정보를 분류해 보도록 하겠습니다.
cafe.naver인지, blog.naver인지 아니면 다른 사이트인지 확인입니다.
hrefs=[]
for i, post in enumerate(posts):
href=post.find("a", attrs={"class": "sub_txt sub_name"}).attrs['href']
hrefs.append(href.split('//')[1].split('/')[0])
df=pd.DataFrame(hrefs).value_counts()
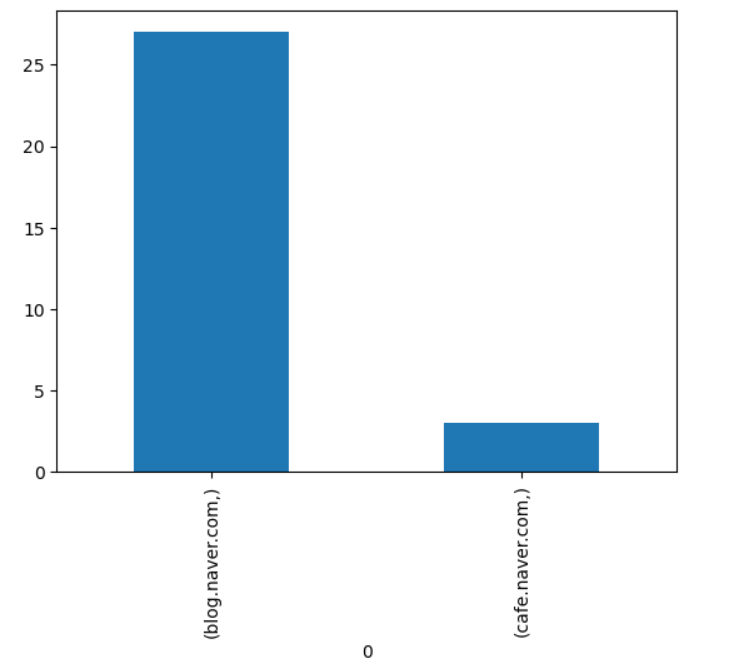
df23-02-15일 현재 경포대 맛집에 대한 결과 중에서 blog.naver가 24개, post.naver가 4개, cafe.naver가 2개 분포되어 있습니다.
hrefs=[]
for i, post in enumerate(posts):
href=post.find("a", attrs={"class": "sub_txt sub_name"}).attrs['href']
hrefs.append(href.split('//')[1].split('/')[0])
df=pd.DataFrame(hrefs).value_counts()
df
df.plot.bar()
다른 검색어로 변경해서 해보도록 하겠습니다.
한국은행 API에 대한 결과인데 다양한 사이트가 30개 안에 포함되어 있는 것을 알 수 있습니다.
keyword='한국은행 API'
query = keyword.replace(' ', '+')
url = "https://search.naver.com/search.naver?where=view&sm=tab_viw.blog&query=" + query + '&nso='
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, "lxml")
review=soup.find('div', class_='review_loading _trigger_base')
posts = soup.find_all("li", attrs={"class": "bx _svp_item"})
hrefs=[]
for i, post in enumerate(posts):
href=post.find("a", attrs={"class": "sub_txt sub_name"}).attrs['href']
hrefs.append(href.split('//')[1].split('/')[0])
df=pd.DataFrame(hrefs).value_counts()
df
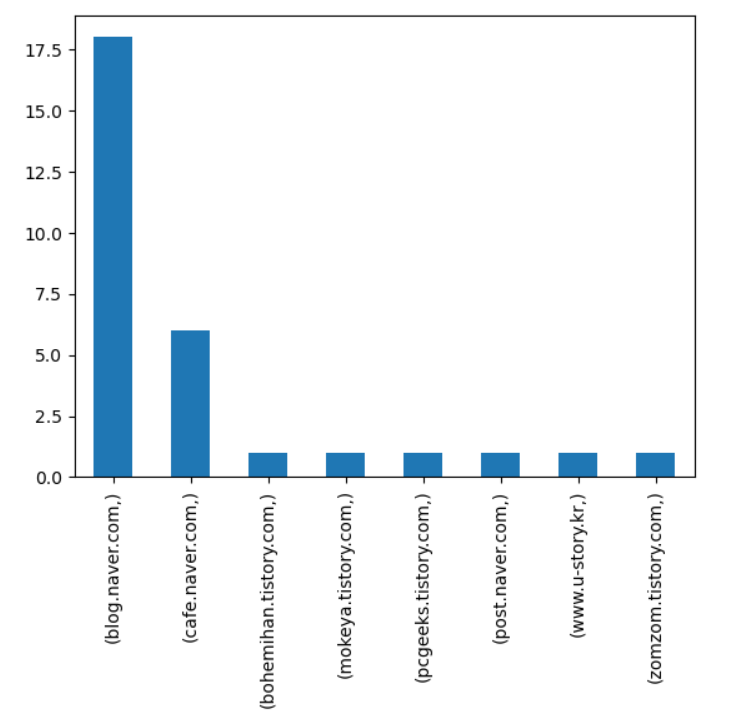
겨울 여행지의 검색어에 대한 결과 입니다.
blog.naver와 cafe.naver만 포함되어 있네요.

이상으로 네이버 뷰를 크롤링해서 검색어에 대한 링크정보를 확인해 봤습니다.
'API' 카테고리의 다른 글
| [통계청 API] 가입 후 API key 신청 및 확인 (4) | 2023.02.21 |
|---|---|
| [한국은행 API] 우리나라의 국가별 수출총액 수집 및 과거데이터 비교 (4) | 2023.02.17 |
| [공공데이터포털 API] SRT 운행월별 정차역별 승하차인원 (8) | 2023.02.13 |
| [Fred API] 실업률과 비농업고용 및 기준금리 비교 (4) | 2023.02.09 |
| [한국은행 API] 국채와 회사채 수집 및 신용스프레드와 주가 (4) | 2023.02.07 |



